

Published in carrier-bag.net , 28 March 2025. Focus: If AI was the answer, what was the question, again?
Neither natural nor intelligent
‘Artificial intelligence’ (AI) is such a large, dynamic, and vaguely defined field that much of what can be said about it is both true and false, or no longer true or possibly not yet true. Even to relatively clear questions, such as whether self-steering cars, as they have been announced for years, already exist today, the answer is yes and no .
This vagueness is due not least to the term artificial intelligence itself, which was first used in a funding application for a scientific conference held in 1956. In a narrow sense, then as now, AI serves as a broad, generic term that encompasses different applications and technologies that have very little in common. As such, it refers to a large, heterogeneous class of software that can recognize, evaluate and, in the case of generative AI, recombine patterns in data based on statistical or logical models. Presently, statistical models dominate, but that has not always been the case and does not need to be the case forever. One of its key characteristics is that these applications can use informational feedback to improve the recognition, evaluation, and recombination of patterns regarding a specific criterion.
But there is much more to the term AI than just ‘self-optimizing algorithms’. ‘Intelligence’ brings it close to the supposed uniquely human capacities, and the ‘Artificial’ promises almost unlimited technical enhancement potential. Both terms produce an enormous evocative surplus, as well as many analytical traps. For we neither know what is meant by intelligence—beyond an assumed specificity of human thought—nor is it clear whether or how past developments can be extended into the future, nor whether the ‘artificial’ can be so easily separated from the ’natural’. But it is this very vagueness that opens up a wide speculative space, expansive enough to accommodate a sheer infinite amount of prognostications about impeding doom or salvation, that enabled this term to survive for 70 years in the fast-moving IT industry, despite various crises .
To take a critical approach to the current phenomenon of ‘generative artificial intelligence’, it is therefore worth putting the notion of intelligence and of the artificial aside and focusing entirely on the generative. What exactly is being generated here? In the following, I want to look at two aspects of this generation. First, the character of the generated content, in particular, the generated images. And, second, the generated political economy, that is, the new power structures emerging from this commercial field. The aim of this text is twofold: to draw these two dimensions together, as they are closely interrelated but usually treated separately; and, focusing on two, exemplary artistic projects, to show that there is no techno-determinism at work. Rather, this field could, and should, be configured differently, particularly from the perspective of creating a more egalitarian version of democracy.
Analytical vs. generative AI
Before focusing on the specific dimensions of generativity, it’s useful to distinguish between analytical and generative AI. Technically, there is no fundamental difference. In each case, it is a matter of recognizing and evaluating patterns in data. The difference lies in the application . In the first case, the aim is to make statements about this data, in the second case, to create something new from it. Analytical AI that recognizes and classifies patterns is already widespread today. And not just recently. Spam filters that can improve themselves based on informational feedback from users have been in use since the late 1990s. The transitions between the two categories can be fluid. The differences are clearest and most far-reaching from an epistemological perspective. To put it simply, analytical AI can be correct to varying degrees, while generative AI cannot. In the first case, we can apply analytical-empirical criteria that draw a distinction between ’true/false’ in order to evaluate the output; in the second case, we have to apply aesthetic-normative criteria such as ‘beautiful/ugly’ or ‘good/bad’. An image recognition program – a typical example of analytical AI – is being evaluated whether it correctly distinguishes cats from dogs. An image produced by Midjourney or another generative program is evaluated primarily on whether the viewer likes it or not. Again, the transitions are fluid. From this perspective, translation software is probably more analytical because it can make obvious mistakes that we can easily classify as ‘false’. However, it also contains generative elements when several equally correct translations exist for certain passages. Since there are no direct mistakes in either of them, we need to apply aesthetic criteria, that is, whether we like the version presented to us, or would prefer another one.
Generated Content

Pope, image generated using Google Gemini, end of February, 2024
In my opinion, these synthesized pope images are some of the most interesting that have been generated to date. They were created using Google Gemini, which was released at the beginning of 2024. The technical quality is impressive, quasi photo-realistic, and very rich in detail. However, the images went viral as a supposed wokeness scandal. The prompt ‘Generate an image of a pope’ presented people of different genders and colors as popes! Critical scientists, particularly women of color, have been talking about bias and discrimination through AI for years, yet this discussion suddenly reached the mainstream when white men felt discriminated against. Sundai Pichar, CEO of Google, had to apologize publicly. But for what? For a lack of historical accuracy? There is a broad consensus among historians that there has never been a female pope. The critical study of the sources offers no evidence. But such a historical approach corresponds neither to the method nor to the claim of image generation.
Generic Pastness
Generative methods build on patterns that have been extracted from an existing data set (training data), for images that are assumed to be relevant, such as those with the label ‘pope’. And this data set is likely to contain also images of a female pope.
Woodcut by Jacob Kallenberg (Boccaccio: De Claris Mulieribus, Apiarius, Bern, 1539)
Although many people complained that these images were wrong, the nature of the images makes such a claim meaningless. These images may look photo-realistic, they have nothing to do with photography. The criteria of photographic theory, such as representation, indexicality, or framing, do not help us here. If we were to try to change the image frame or the point of view, to look beyond the image – approaches that would be essential for classical photographic theory – we would not get a broader picture of reality. Had the generated image better matched the expectations of those who were outraged at the ‘Indian popess’ – by depicting, say, an old white man with a beatific smile – it would have been no more historically accurate than the image of the popess. Generated images, according to cultural scientist Roland Meyer, show something like a “generic pastness ”, an endlessly varied, idealized or clichéd retrospective that revolves around the same pattern. This brings them close to propaganda narratives of the past. And, as we know, these usually have little to do with historical truth, even if many people are more than willing to accept them as such.
Generated content is not a representation of an external world, but variations of patterns in data, assembled into something that did not exist before. Their content is therefore not to be determined analytically and empirically, but aesthetically and normatively. We have to ask ourselves whether we like them and regard them good or bad. And many people obviously found the image of a female or black pope deeply problematic. It was something they didn’t want to see, something ugly, monstrous. The epistemologically confusing thing about these images is that they neither show something that objectively exists in real space, nor something fictional that arises from the subjective imagination, as we are used to from art or literature. Rather, what these images show is a world that does not exist, but which is conceivable considering the past (data set) and the present (generative models) and could therefore exist.
Like all historical propaganda narratives, their gaze is not directed backwards, but forwards. They are an anticipation, a premonition of the future. These images show something virtual in the classical sense of Gilles Deleuze , something that is possible, that already affects the real, but is not fully actualized. What the images show are correlation clusters in the ’latent space’, which, consisting of past data organized according to the current state of technology, contains all currently possible future states. Through mere generation, image content does not become fully real, that is, actualized in the present. Rather it is shifted, sometimes more, sometimes less, towards reality. Generated content, in other words, gives us clues about possible futures and actual pasts. So, if the far-right loves generated content and uses it extensively in its propaganda, it’s precisely because they have an aesthetic understanding of politics. Both, in the sense of Walter Benjamin – as a way of creating expressions of dissatisfaction while preserving property relations – and as an understanding of politics where advanced technological means get used as generative force towards a retro-utopia. The latter was identified by the political scientist Jeffry Herf in the 1980s as “reactionary modernism ”. Seeing is believing! Or, at least, once seen, it’s hard to unsee and remains stuck in the imagination.
Statistical and other values
By and large, we know how generated images come about. There is a statistical analysis of a relevant group of images, grouped together in the latent space by labels shared ‘portraits’ and/or ‘pope’. From these, patterns are extracted that are typical for these groups. By repeating these patterns, with a certain degree of randomness at different points in the process, new images are created. Because the targeted use of randomness is kept within narrow limits, each image is unique, but somehow they all look very similar. However, if only these statistical techniques had been used in Google Gemini, it is unlikely, but not impossible, that these images would ever have been created, since the subset of images representing a portrait, a pope and a woman is statistically small, but, as we have seen, non-zero.
But we also know that no commercial generative AI works in this way alone. They all have ‘guard rails’, that is additional rules explicitly added to draw normative boundaries around certain sections of the latent space (for example, to prevent instructions on how to build weapons or information about OpenAI’s critics ) or change weights to give ‘desirable’ patterns higher probabilities.
One aim of these guard rails can be to correct what is perceived as distortions in the training data. This is achieved by assigning a greater or lesser weight to certain variables or keywords than would be assigned to them based on the statistical distribution in the training data. There are many legitimate reasons to do this. For example, if AI were trained to sort job applications using only the data of previously successful applicants, many forms of previous exclusion would simply be automatically perpetuated, which would run counter to politically desired efforts to achieve greater diversity in the workplace . The images of popes generated by Google Gemini were, as Google itself explained , probably the result of a correction of the under-representation of people of color in the training data.
It was not least this intervention that many, particularly on the political right, objected to. For them, it was an example of the ‘woke thought police’. They are not entirely wrong about that. After all, who authorized the managers and engineers at Google to make these decisions? What are their qualifications and what are the criteria? Who benefits from them and who suffers? These are legitimate questions that should be resolved in a way that produces accountability.
But this is the opposite of what the far right wants. As is so often the case when right-wing populists point out real problems , their approaches do nothing to solve them. On the contrary, it makes them worse. In effect, they want to impose simply a form of thought police that suits them. Elon Musk explicitly positions his generative AI, Grok, as ‘anti-woke’ without it functioning in any fundamentally different way. Indeed, there are by now many examples of how Grok is steered away from politically inconvenient, but statistically correct, statements.
The design of such guard rails is inevitably a political process. Which characteristics in the existing data sets should be corrected and in what form this correction should be made cannot be answered in a value-free manner. Again, aesthetic-normative rather than analytical-empirical questions arise. It is less about what an accurate representation (of what?) really is, but rather which version of the possible should be realized.
For the data and computer sciences, which see themselves as technical disciplines, this is a fundamental dilemma that cannot be solved analytically. Not even by rejecting guard rails entirely. Taking historical data as an unproblematic representation of reality (‘ground truth’) is highly problematic. Every historian knows these problems with archival records. They never speak simply truth but contain the perspectives of their makers. Using data without guardrails would not be any more objective, rather it would mean to automate and thus perpetuate historically evolved forms of privilege and marginalization. This highlights again that we need to apply the aesthetic/normative criteria to understanding these images, which makes them invariably political. For the far right, however, the performative rejection of such guard rails, serves a double purpose. First, by reproducing past discrimination and presenting it as high-tech future, it smoothly aligns with reactionary modernism. Second, by transposing politics to a field of assumed technical objectivity (math never lies!), it renders it nontransparent and beyond question.
Yet, every image is the result of a highly situated production. In the case of generated images, this situatedness is characterized by the historical and political nature of the data, as well as by the values and interests of those who create models from it. As a result, the boundary between what can exist and what should exist becomes blurred. In one way or another, it is decided here which versions of the future can be articulated at all. A look at the situatedness of technology shows that there is no technological determinism at work here, but rather concrete institutional dynamics that are determined not least by the underlying data and the built-in norms and guard rails. This gives the premonition element of the images a distinctly political character.
Another world can be generated
But if there is no technological determinism at work, this means that entirely different worlds could be generated. Such an interest pervades the work of the German-Iraqi artist Nora Al Badri, for example.

Nora Al Badri. Babylonian Vision, Gan Video, 2020 (Video Still)
One of her works is Babylonian Vision (2020). For this, she trained a neural network, a so-called Generative Adversarial Network (GAN), a precursor to current image-generating processes, with 10,000 images from the five museums with the largest collections of Mesopotamian, Neo-Sumerian and Assyrian artifacts. From these, further new artifacts have now been generated in the form of videos and images and presented in the exhibition space as objects of speculative archaeology.
The work deals with two core questions of image generation. Firstly, how does the data of the past, with which machines are trained, bear the traces of its own, often violent, history? This is already evident in the question of access. Although all museums were approached, most of the large collections did not make their data available, some by erecting insurmountably high administrative walls (such as the requirement to fill out one form for each image). So they had to be obtained by other means. Where does this refusal of museums to allow access to their data come from, even though it would be technically and legally easy? Who is allowed to work with these objects/data? To what extent is a colonial order of knowledge being perpetuated in the digital world?
However, Al Badri goes beyond these questions, which are at the center of many restitution debates. For she also poses the question of the interpretation of the past, not so much in the sense of historical source work, but as a resource for the future. Here, too, the element of anticipation resonates. Whose values, whose interests flow into the treatment of cultural resources as building blocks for the future? Is the backward-looking view of museums, with their focus on authenticity, the only legitimate approach?
By training with selected data, the work creates its own latent space , which can open up futures that are less dominated by colonial legacies and commercial optimization. Other images can be generated in this space. New speaker positions become possible. The absent is helped to become present. The explicitly speculative nature of this work takes the normative-aesthetic dimension of generation seriously. However, it is not limited to a consumerist menu with four versions, one of which can be selected according to individual preferences (the standard method of commercial offerings). It poses these questions in the collective space of the exhibition. With such different images and a different setting, a different future becomes, at least potentially, conceivable. Of course, thinking is not acting, and acting is not necessarily successful. But without a different way of thinking, a different way of acting is not possible.
Political Economy
There are, of course, limits to what alternative image generation approaches can do, not simply because of their scale, but because the generative aspects of generative AI are not limited to the screen. Indeed, they extend far beyond the screen. To approach this other dimension of generativity, it is useful to do what Geoffrey Bowker called “infrastructural inversion” , that is, to shift the focus from the figure (the image in the screen) to the ground (the vast infrastructure that produces it).
If we look at the material basis of generative (and analytical) AI, we see a transcontinental, industrial infrastructure for networked computing, anchored in ever larger, now even ‘hyper-scale’ data centers , with thousands of physical servers and millions of virtual machines. Its dynamics entail strong elements of centralization because the underlying economies of scale – regarding data, models and infrastructure – create a positive feedback loop favoring the largest players, making new entries into the field progressively more difficult. To bring this into view, it’s useful to understand AI not as a set of specific, stand-alone applications, say image generation, self-driving cars, pattern recognition for detecting anomalies or making prediction, but as an integrated, multi-modal, multipurpose infrastructure, much like the Internet itself. In less than four decades, the Internet, as we all know, has become a core layer of the operating system even for processes that remain predominantly analog, such as train systems or flood levies. AI is now being aggressively pushed into all aspects of computing, that is, into the entire infrastructure at large. Once it’s embedded, it will be impossible to remove, as the processes will have adapted to the possibilities of the new technology and society will come to accept its downsides (much as we seem to have resigned ourselves to near daily occurrences of large-scale security breaches in conventional networked systems, or the toxic onslaught of daily communication through email and messenger apps). On the consumer end, this can be seen with, often unwanted, AI applications being added to existing programs. On the institutional side this is most visible with Elon Musk’s hacking the American federal bureaucracy , firing people en masse, extracting public data and remolding the administration through the pervasive use of AI . While the bleeding out and reconstitution of the federal bureaucracy in the US is spectacular, similar processes are occurring in Europe as well, by thousands of small cuts.
AI as next-level networked computing
If we understand AI as the next phase in the built-out of the networked computing infrastructure, we can divide this history into, broadly speaking, three phases. The first phase started in the early 1980s, when the first group of major Internet standards consolidated, turning networked computing from an experimental playground into an infrastructure people and institutions came to rely on. During that time, the infrastructure was largely decentralized, both in terms of technologies and communication patterns. While not all layers and aspects of the early internet were decentralized, its defining technologies, such as E-mail, IRC (Internet Relay Chat), and the WorldWideWeb, were. They were based on open protocols that enabled independent machines to exchange data across institutional and technical boundaries. People could directly communicate with other users, no matter whose machines they were using. Every mail server could, and still can, exchange messages with other mail servers, no matter who owned it or whether it was part of a public, private, profit or non-profit infrastructure. This focus of open exchange and collaboration reflected the non-commercial and research ethos that shaped much of the culture of this period.
The next phase, which started after the dot-com crash in March 2000, brought about a massive centralization of the infrastructure, while keeping the communication largely decentralized. This was the period of the big platforms like Facebook, which introduced closed networks, displacing email, the web and decentralized chat/messaging with their own proprietary solutions. This funneled many of these early promises of the Internet, such as the democratization of publishing, into user-friendly interfaces. It seemed to further the optimistic visions of the Internet, as the patterns of communication – users speaking directly to one another – remained decentralized. As nearly everybody rushed to these new platforms, the fact that they were walled gardens was barely noticeable at first. However, the underlying centralization of infrastructure gave the owners of the infrastructure not only enormous influence over the forms and patterns of communication, but also created very large-scale data sets, that were initially used to offer targeted ads and personalized services. The companies that arose in this period made the data-center the defining element of this infrastructure. Google built its first own data-center in 2006, Facebook in 2011. Quite intentionally, this shifted the balance of power towards the infrastructure providers, who first used it to consolidate their monopoly dominance and then to extract ever higher profits (which users experience as ‘enshittification ’).
The boom of generative AI, which started with the maturing of generative Large Language Models (LLMs) around 2020, can be seen as the next step in this process of centralization. This now not only takes place on the level of the infrastructure, but also regarding communication patterns. Users of chatbots are no longer talking to each other, but now they are interacting with central entities, the LLMs, whose data sources are opaque, and in most cases they do not point beyond themselves. Rather, they draw people deeper and deeper into their vortex by suggesting that reformulating the prompt is the best way to improve results. The solution is always just one prompt away.
On the level of networked computing infrastructure, the fact that Generative AI is a continuation of a long-standing trend of centralization and concentration of power is best illustrated by the dominance of the five big tech companies in the second phase of development: Alphabet, Amazon, Apple, Meta, and Microsoft. The cloud is the link that provides continuity between the two phases. By owning the data-centers, as capacity to run largest-scale computing and as a place to gather, store and process massive data sets, they are strategically placed to control the hardware layer below and the software layers above. As Nick Srnicek showed , not only are many of them branching into development of hardware, in particular AI-optimized CPUs (Google started developing their own Tensor Processing Units (TPUs) in 2015). In addition most of the foundation models, both proprietary and open source, are controlled by these companies to take advantage of their massive data hoards for training, and give them strategic influence over all the applications built on top of them.
The black cloud as the seat of power
The concentration of power is not only the effect of the economies of scale, which favor data-centric incumbents, but also of the black-box character of the technology itself. Indeed, one could say that the fusing of the two, the cloud and the black box, creates a new entity, the black cloud (or, as Elon Musk calls it, “dark maga”), looming over the horizon. One aspect of its blackness is a feature of the technological design that makes it difficult to understand what really goes on inside the models. Even with so-called explainable AI, or the current wave of models that seem to reason in explicitly stated, logical steps, the relationship between these explanations and the underlying processes remain murky. They are too complex and too dynamic to yield to stable cause-effect analyses, its correlations all the way down. And as Justin Joque has argued , it’s a feature, not a bug, that these correlations can change at any time. After all, if they remained stable, there would be no learning. But learning here is reduced to improved short-term prediction, reflecting a limited view of truth as a risk/reward calculation, typical for financial markets for which many of the mathematical formulas were first developed.
But the blackness is made even blacker, reaching the near total light-absorbing qualities of Vantablack used by the artist Anish Kapoor, through additional layers of organizational, legal, and architectural means. Organizationally, by relying on a poorly documented, global division of labor, that makes it nearly impossible to fully understand the character of the inputs into this infrastructure and their relationship to one another. This makes it easier to hide exploitative labor practices and environmental costs. However, this is not just a question of inevitable complexity, but also one of deliberate institutional design. For example, OpenAI is formally a non-profit, yet practically, it is an investor-driven company on a hyper-growth trajectory. In terms of ownership, it’s an independent company, but it’s entirely dependent on investments from Microsoft for its computing infrastructure and (forced) integration into its products as a path to profitability . By legal means, through the pervasive use of non-disclosure agreements and trade-secrets (rather than copyright or patents which require publishing), that bind even public entities from disclosing basic information such as the amount of water allocated to a specific data center on its territory. As architecture, by designing data-centers as closed, high-security facilities, bland boxes located according to geophysical and geopolitical criteria, and hiding much of the rest of the infrastructure as much as possible. This extra blackness of the cloud is strategic, and it contributes to a theme that runs through this new regime: power without accountability. Its character is best encapsulated in Little Britain’s sketches: The Computer Says No!
This emerging political economy is about to supplant the previous mode of “surveillance capitalism” as Shoshanna Zuboff analyzed it. Its main lever of operation is no longer the modification of behavior, but rather, the modification of life chances. The emblematic tool of surveillance capitalism was the consumer profile, based on which targeted ads and other psychological operations could be launched to steer commercial or political activity. The power of such profiles to affect people was the dubious claim-to-fame of Cambridge Analytica . The emblematic tool of the new regime of generative AI might well be the AI-driven job application filter, which shapes not attitudes but life chances. They either open or close the door to employment without any recourse, not even against forms of discrimination based on gender, ethnicity or religion, explicitly prohibited by the law. Accountability is the exception — only in very rare cases can a tool be opened up and the mathematical functions that do the shaping (which is often discriminatory) be pinpointed.
Peering into the black cloud
To even begin to pierce the blackness that allows for the creation of imperial power without accountability, it is necessary to understand the extent of the infrastructure and the many instances in which it is materialized, and the conflicts generated on the ground. Each of these conflicts is a chance to intervene, to configure the infrastructure differently.
One of the substantial attempts to map the infrastructures of AI is the work Anatomy of an AI System by Kate Crawford and Vladan Joler.
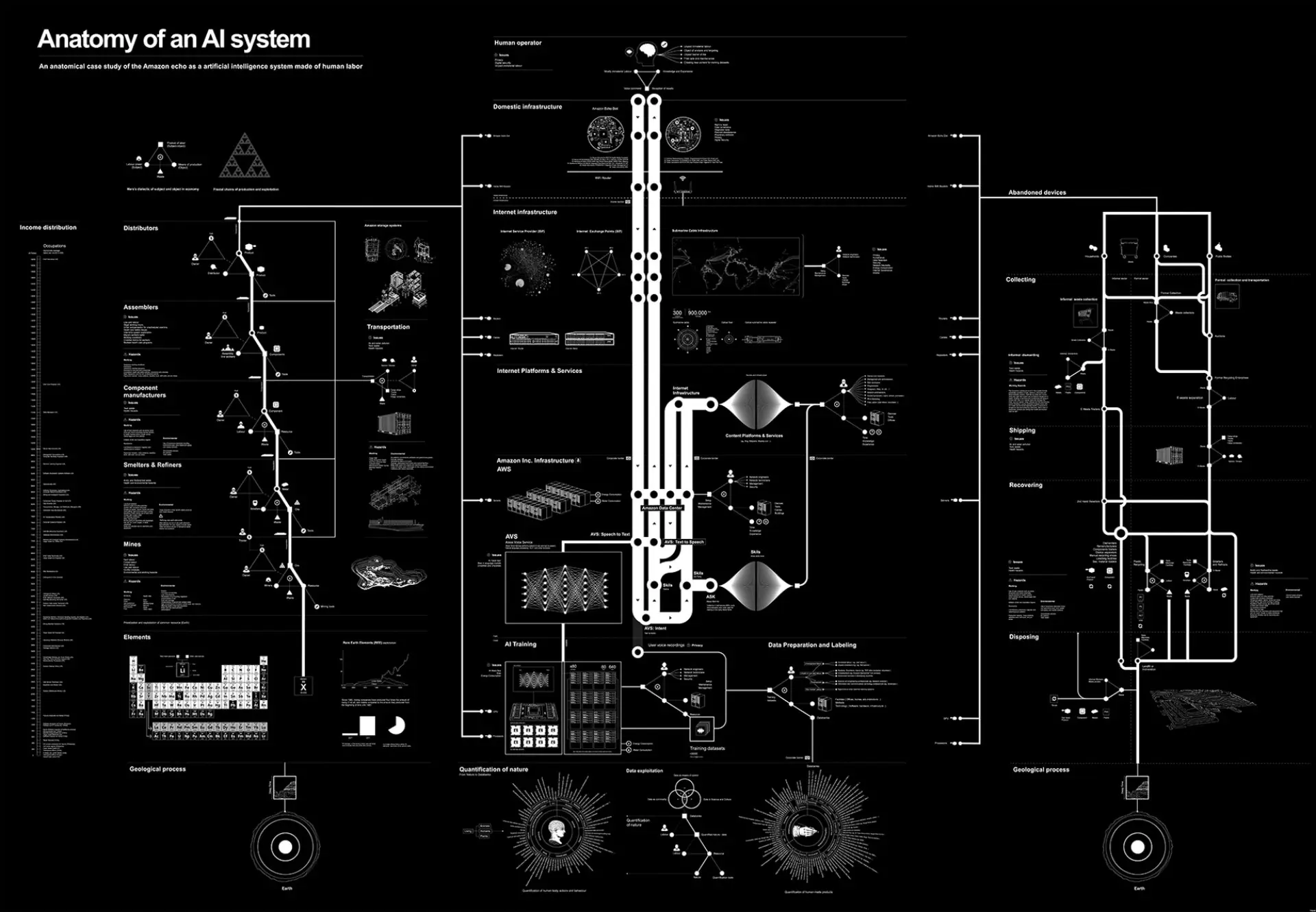
Infrastructure of an AI System (Kate Crawford & Vladan Joler, 2018, anatomyof.ai )
The visual analysis of the Amazon Echo infrastructure traces the device’s life cycle from the extraction of raw materials (birth), its operation through physical and cognitive layers (life), to its eventual disposal (death). It all begins and ends with geology: from the mines, which take minerals that were created over millions of years, to the e-waste dumps where pollution stays in the ground for hundreds if not thousands of years. All for a brief lifetime of planned obsolescence. What becomes visible are the concrete steps through which the exploitation of labor and nature in mines, factories, outsourced office-cubicles, and society at large takes place. Impressive in this work is not just the detailed research that went into it. This is also presented in Crawford’s book Atlas of AI (2021). What is unique is the aesthetics, the ability to produce an account of the entire system, that balances the need for detail with the need to see the system in its entirety. Of course, a holistic analysis cannot show everything. So the focus on exploitation in service of convenience for the few is key to tame complexity in favor of narration. This is highlighted by including, on the right-hand side, a scale of hourly wages of the different professions involved. It would take a person working in an improvised mine in the Democratic Republic of Congo 7,000 years of non-stop dangerous and back-breaking work to earn as much as Jeff Bezos, sitting at the top of the pyramid, earns in a single day. While the black cloud is the form of obfuscation that the new regime takes on, the map presents an aesthetic that allows us to find places to mount challenges and perhaps even see their interconnections. If the shared experience on the factory floor provided ground for solidarity against the first form of capitalist exploitation, then the aesthetics of systems, and the ability to locate oneself within them, will play a role in finding new sources of solidarity.
Outlook
There are powerful synergies between the types of premonition by generated content, the centralization of infrastructure, and the unaccountability of power in the black cloud. Together, they create a contemporary version of reactionary modernism that has given itself many different names, such as Techno-Optimism or effective accelerationism . Infrastructural and political logics are closely aligned and the race for ever larger data-centers, ever more data, ever more energy, and more minerals further entrenches these mutually reinforcing dynamics. But there is no technological determinism at work here, as much as the merchants of doom and hype want us to believe. Other worlds, compatible with a renewed sense of democracy and common possibility, can be premonitioned. The black cloud can be rendered legible. And it’s not even necessary to achieve full transparency before we can begin to act. The identification of already existing conflicts embedded in the constitution of the infrastructure opens up spaces of agency. New aesthetics, new ways of seeing the world, are key to this endeavor.
And even dynamics that centralize infrastructures into the hyper-scale, with the associated political, social and ecological dynamics, are not following some inert law, but are strategic decisions. And questionable ones at that. The appearance of the Chinese DeepSeek application caused a tremendous shock in Western circles. Not only because China is catching up, which is taken to be a bad thing in the climate of geopolitical rivalries, but because it might be a glimpse into a branching pathway for the development of AI applications where powerful tools can be developed on a much smaller scale and thus outside the black cloud.