Technology and autonomy in more-than-human networks
8 January, 2024 - 15:11 by felixInfrastructure of a migratory bird. Technology and autonomy in more-than-human networks
With Gordan Savičić, at 37C3, 28.12.2023 (file source)
Infrastructure of a migratory bird. Technology and autonomy in more-than-human networks
With Gordan Savičić, at 37C3, 28.12.2023 (file source)
 内容简介:当前的文化与政治等诸多方面均受到数字状况的影响。本书认为,这种 影响涉及更多的人参与到有争议的社会意义的协商中。更多的人利用复杂的 通信基础设施,同时又被社交媒体所主导,不仅引发了当前的文化、社会与政 治现象,还导致新的行为方式的产生。作者认为,这种状况有三个关键的成 部分:利用现有的文化材料进行自己的生产,通过集体来努力地建立新意义的 方式,以及算法与自动决策的潘在作用,三者界定了“数字状况”,作者田洲 了导致当前状况的历史性结构转型,还研究了这种新文化造成的深远的政治影 响,附录文章《数字团结》的出发点,是2008年全球经济危机爆发后出现的网 格化政治组织形式的新浪潮。作者繼卡尔·马克思之后,阐述了在当前应用创 新和技术进步,与组织或限制这种进步的经济机构之间的矛盾,生产力与生产 关系之间的矛盾被置于如下背景中:我们已经永远地离开了麦克卢汉的古堡 星系,关于我们将抵达哪里的斗争才刚刚要开始。本书对于关心艺术、媒介、 传播、社会、政治与文化研究,以及想要了解今天的文化与政治正在发生的变 化的读者必不可少。
内容简介:当前的文化与政治等诸多方面均受到数字状况的影响。本书认为,这种 影响涉及更多的人参与到有争议的社会意义的协商中。更多的人利用复杂的 通信基础设施,同时又被社交媒体所主导,不仅引发了当前的文化、社会与政 治现象,还导致新的行为方式的产生。作者认为,这种状况有三个关键的成 部分:利用现有的文化材料进行自己的生产,通过集体来努力地建立新意义的 方式,以及算法与自动决策的潘在作用,三者界定了“数字状况”,作者田洲 了导致当前状况的历史性结构转型,还研究了这种新文化造成的深远的政治影 响,附录文章《数字团结》的出发点,是2008年全球经济危机爆发后出现的网 格化政治组织形式的新浪潮。作者繼卡尔·马克思之后,阐述了在当前应用创 新和技术进步,与组织或限制这种进步的经济机构之间的矛盾,生产力与生产 关系之间的矛盾被置于如下背景中:我们已经永远地离开了麦克卢汉的古堡 星系,关于我们将抵达哪里的斗争才刚刚要开始。本书对于关心艺术、媒介、 传播、社会、政治与文化研究,以及想要了解今天的文化与政治正在发生的变 化的读者必不可少。
边界计划:“边界计划”是由中国美术学院雕塑与公共艺术学院在2020年启动 的研创计划,它深信艺术不仅能够,也必须在突破与划定边界之间不断追问和 演绎,其研究出版的首个方向围绕雕塑与公共艺术,传递与艺术作为一个“形 “象”的文化与社会意义相关联的普遍性问题:再由“数字奠基”接力,触发有 关当下及未来的感受力与艺术力。“边界计划”提倡一种“阅读”的过程,并 与来者共筑一个无界却有形的生态.
This book is a translation of two of my books


Digital Condition and Digital Solidarity,
published by the School of Sculpture and Public Art of China Academy of Art. Officially, it will be released in fall 2023, but you can order it already on dangdag.com.

As part of Aksioma's conference "Unreal Data, Real Consequences" (co-produced by with the Latent Spaces research project) I'll give a talk on "Unreal is the New Real" on February 27.
Abstract
 Es freut mich sehr, dass ich einen Beitrag zu diesem Sammelband beisteuern konnte.
Es freut mich sehr, dass ich einen Beitrag zu diesem Sammelband beisteuern konnte.
Commoning als unvollständige Dekommodifizierung (s. 495-513)
Die Commons -- Gemeinschaftsgüter deren Produktion und Nutzung nicht warenförmig sondern Nutzwert-orientiert sind -- werden oft als Gegensatz oder Alternative zum digitalen Kapitalismus gesehen. Bei genauerer Betrachtung ist das Verhältnis der beiden Systeme aber deutlich ambivalenter. Denn während die Überwindung der Warenform neue Potentiale post-kapitalistischer Ökonomien konkret sichtbar macht, ist es dem digitalen Kapitalismus in der Praxis weitgehend gelungen, diese Potentiale einzuhegen und für seine Zwecke nutzbar zu machen.
So werden die Commons heute vielfach dafür eingesetzt, Güter und Dienstleistungen bereit zu stellen, die der digitale Kapitalismus selbst nicht produzieren kann. Sei das, weil zwar ein Bedarf, aber kein Markt für gewisse Güter und Dienstleistungen besteht, sei es, weil Konkurrenz und geistiges Eigentum in seiner konventionellen Form notwendige Formen der Zusammenarbeit in hoch-komplexen Teilen der Wissensökonomie behindern. Hier werden die Commons als Feld der “präkompetitiven Kooperation” von kapitalistischen Akteur:innen teilweise direkt finanziert.
 After 25 years (!) of moderation and other near-daily caretaking work by Ted Byfield and myself, a fresh crew has taken over the nettime mailing list. It's not easy to step into a project that has such a long history, so I'm grateful to Jordan Crandall, Menno de Groot, Christian Swerz, and Paul van der Velt to step up and take on all the janitorial tasks that are necessary to run a social project -- online or offline.
After 25 years (!) of moderation and other near-daily caretaking work by Ted Byfield and myself, a fresh crew has taken over the nettime mailing list. It's not easy to step into a project that has such a long history, so I'm grateful to Jordan Crandall, Menno de Groot, Christian Swerz, and Paul van der Velt to step up and take on all the janitorial tasks that are necessary to run a social project -- online or offline.
I'm sure they will not simply maintain the list and the community, but infuse it with new life and give it their own direction.
You can read their announcement "new mods, new nettime-l". Our friends from servus.at, a non-profit netculture initiative in Linz. Austria, provide hosting.
it's hard to overstate how important the list has been for me, intellectually, but also professionally, personally, socially, and emotionally.
And still is, but now as a simple subscriber and occasional contributor to the list.
El crecimiento de las principales plataformas de medios sociales ha sido tan rápido que resulta difícil imaginar nuestra vida cotidiana sin ellas. Sin embargo, Facebook, con 2.900 millones de usuaries, aún no ha cumplido 20 años. Twitter, utilizado por 330 millones de personas, se creó en 2006, e Instagram, utilizado por 1.200 millones de personas y ahora forma parte de Meta, la empresa matriz de Facebook, se creó en 2010. Sin embargo, su espectacular ascenso hace olvidar fácilmente que la práctica de la comunidad digital se remonta mucho más atrás. El deseo de estar en contacto con personas afines, vivan en el mismo barrio o en otro continente, ha sido uno de los motores del desarrollo cívico de Internet desde el principio.

This is a revised version of my presentation at the New Alphabet School#3 Coding at Goethe-Institut Max Mueller Bhavan, New Delhi on January 16, 2020. Originally published at the New Aphabet's website.

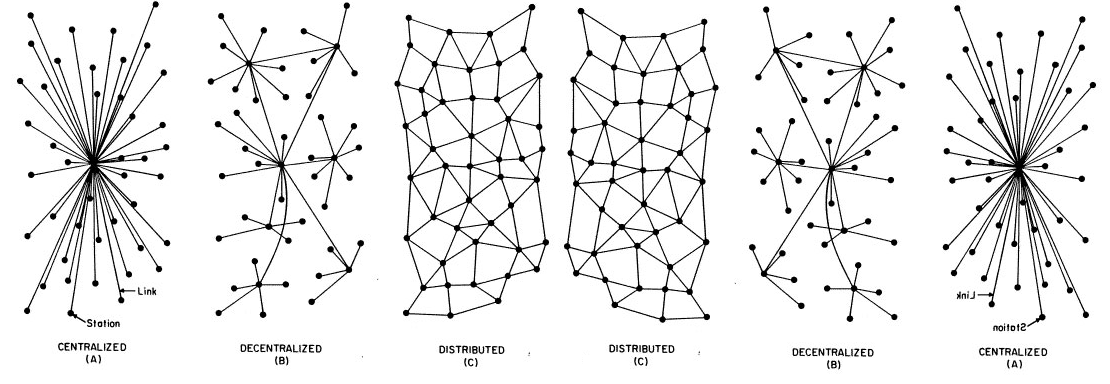
One of the relatively little-discussed phenomena in the social critique of AI is the fact that it is not only a centralizing technology, but also one that increases the distance between people and the power of the owners of the coordinating infrastructure. Of course, there is no direct determinism of the infrastructure, but it matters in which way the playing field is tilted.
This is an unoffical translation of "Die Sozialen Medien am Kipppunkt" (Le Monde Diplomatique, March 2022)
![]()
The growth of the major social media platforms has been so rapid that it's hard to imagine our daily lives without them. Yet Facebook, with 2.9 billion users, is not yet 20 years old. Twitter, which is used by 330 million people, was created in 2006, and Instagram, which is used by 1.2 billion people and is now part of Facebook's parent company Meta, was created in 2010. However, their spectacular rise makes it easy to forget that the practice of digital community goes back much further. The desire to be in touch with like-minded people, whether they live in the same neighborhood or on another continent, has been one of the drivers of the Internet's civic development from the very beginning.
Even before the emergence of the World Wide Web in the early 1990s, mailing lists, Usenet groups (thematic discussion forums) and bulletin board systems (local computers that could be accessed directly via modem) provided a variety of platforms that enabled technically savvy users to exchange information and to network. The commercial service providers from Silicon Valley merely made this practice socially mainstream by creating user-friendly offerings that were enormously profitable for the investors.
![]()
Ich habe in der LeMondeDiplomatique (März 2023, S 3) über die Krise und Chancen der sozialen Medien geschrieben.
Das Bedürfnis nach horizontaler Kommunikation, das seit den Anfängen des Internets die Entwicklung wesentlich beeinflusst hat, ist ungebrochen. In die Krise geraten ist deshalb auch nur ein ganz bestimmtes – wenn auch in der letzten Dekade extrem einflussreiches – Modell, wie dieses Bedürfnis organisiert wird. Mit Mastodon besteht nun zum ersten Mal seit Langem wieder die Chance auf eine nicht rein kommerzielle Infrastruktur für Alltagskommunikation. Und das ist im Hinblick auf demokratische Kommunikation sehr zu begrüßen
Artikel lesen, oder vorlesen lassen.
![]()
Zurich University of the Arts
Latent Spaces (current research project)

Creating Commons (previous research project)
![]()
World Information Institute (Vienna)

Technopolitics Working Group (Vienna)
 Diaphanes, 2021
Diaphanes, 2021
 Polity Press, 2018
Polity Press, 2018
 Suhrkamp Verlag, 2016
Suhrkamp Verlag, 2016
 Buch & Netz, 2014
Buch & Netz, 2014
 PML/Mute, Winter 2013
PML/Mute, Winter 2013
List of all books (according to worldcat)


